JBrowse
- Mature release
- Active development
- Active support

JBrowse is a genome browser with a fully dynamic AJAX interface, being developed as the eventual successor to GBrowse. It is very fast and scales well to large datasets. JBrowse does almost all of its work directly in the user's web browser, with minimal requirements for the server.
Contents
Demo
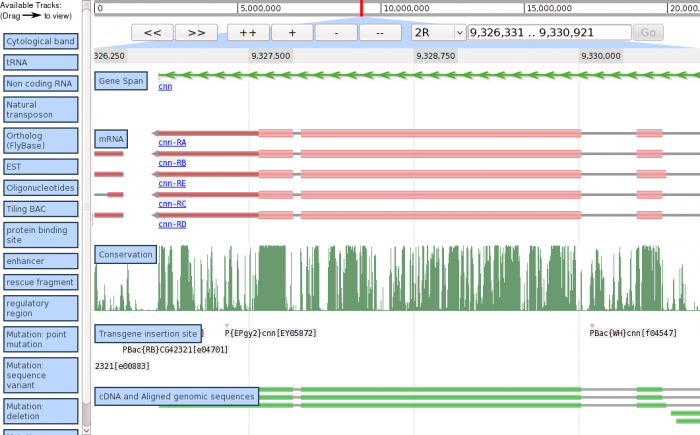
Quick Start: Tutorial
The Getting Started with JBrowse Tutorial provides a basic step-by-step recipe for quickly getting up and running with JBrowse.
Installation
1. Download JBrowse onto your web server.
2. Unpack JBrowse into a directory that is served by your web browser. On many systems, this defaults to /var/www.
cd /var/www tar -xzf jbrowse-*.tar.gz
Make sure you have permissions to write to the contents of the jbrowse/ directory you have just created.
3. Run the automated-setup script, ./setup.sh, which will attempt to install all of JBrowse's (modest) prerequisites for you in the jbrowse/ directory itself. setup.sh does not need to be run as root or with sudo. For the installation to completely succeed, including support for WIG and BAM data, your system must have:
- a working internet connection for downloading Perl modules from CPAN
- compilers for C and C++
-
make - the
svnSubversion client (for fetching thesamtoolscode, needed for BAM support) - development libraries and header files (not just compiled shared objects) for:
- libpng
- Zlib
- GD
For tips on installing these baseline libraries, see JBrowse Troubleshooting.
4. When you can see the included Volvox example data, you are ready to configure JBrowse to show your own data! Proceed to the JBrowse Configuration Guide.
JBrowse Configuration Guide
- Configuration Guide
- Formatting reference sequences (e.g. from FASTA files, or a Chado database)
- Creating feature tracks (e.g. from BED or GFF files, a Chado database, or the UCSC genome browser)
- Creating image tracks (e.g. from WIG files)
- Making features searchable by name
- Removing tracks
- Compressing data stored on the server
- Using callbacks to customize feature tracks
- URL control
- Faceted track selection
- Name searching and autocompletion
- Anonymous usage statistics
- Additional topics:
JBrowse Advanced Topics
For data format specifications, developer information, and so forth, see JBrowse Advanced Topics.
Contact
Please direct questions and inquiries regarding JBrowse to the mailing lists below.
In particular, requests for help should be directed to gmod-ajax@lists.sourceforge.net.
| Mailing List Link | Description | Archive(s) | |
|---|---|---|---|
| JBrowse | gmod-ajax | JBrowse help and general questions. | Nabble (2010/05+), Sourceforge |
| jbrowse-dev | JBrowse development discussions. | Nabble (2011/08+) |
JBrowse Development
JBrowse is an open-source project, started and managed by the laboratory of Ian Holmes at the University of California, Berkeley.
The JBrowse source code repository is kept on GitHub. Please feel very free to fork the code on GitHub and make modifications and improvements, submitting pull requests. GitHub has a very nice tutorial on how to get started with this style of development.
As of January 2012, the lead developer of JBrowse is Robert Buels. Most of JBrowse was originally written by Mitch Skinner.
There is a mailing list for developers, and there is usually a teleconference on the 3rd Monday of the month at 2pm Pacific US time. We welcome participation from Please contact Robert Buels if you would like to listen in or participate.
Presentations
| Date | Presenter | Venue | Links |
|---|---|---|---|
| April 2012 | Robert Buels | GMOD 2012 Community Meeting | |
| January 2012 | Robert Buels | Plant and Animal Genome (PAG) XX | |
| April 2010 | Mitch Skinner | UCSC genome browser group ("genecats") meeting | |
| August 2009 | Ian Holmes | GMOD Community Meeting | Talk summary | PDF |
| January 2009 | Mitch Skinner | GMOD Community Meeting | Talk summary | PDF |
| July 2008 | Ian Holmes | GMOD Community Meeting | Talk summary | PDF |